






---> Темы <---
В этом учебном пособии нейронная сеть может быть обучена непосредственно в браузере. Описываются структура и функционирование нейронной сети как основы моделей ИИ, а также вводятся нейроны и слои как основные понятия нейронных сетей. Кроме того, вводятся понятия числа эпох и связанной с ним скорости обучения как так называемые гиперпараметры, которые могут существенно влиять на процесс обучения моделей ИИ. Наконец, процесс обучения нейронной сети можно использовать для иллюстрации концепции функций активации, которые определяют, как обученные параметры преобразуются в выходы в виде весов и смещений. Если они прозрачно идентифицированы, модели ИИ можно адаптировать и оптимизировать под конкретные требования. Точность модели можно затем оценить с помощью матрицы путаницы и полученной точности. Наконец, понимание ложных отрицательных и ложных положительных результатов позволяет проводить анализ на основе данных в каждом конкретном случае для оценки процесса обучения, качества используемых данных и качества модели ИИ.
---> Цели <---
В целом, учебное пособие посвящено основным концепциям нейронных сетей, упрощенному изложению математических основ, интерпретируемости результатов и возможностям оптимизации. Главная цель учебного пособия — дать понятное объяснение принципа работы нейронных сетей, чтобы способствовать лучшему пониманию моделей искусственного интеллекта.

---> Набор данных <---
Учебное пособие основано на наборе данных (Скачать: CSV) для классификации видов ирисов, содержащем информацию о длине и ширине чашелистиков и лепестков. Набор данных содержит в общей сложности четыре независимые переменные, которые можно использовать для классификации ирисов. Кроме того, есть одна зависимая переменная, которая предоставляет информацию о рассматриваемом виде ириса. Таким образом, это уже известные случаи, на основе которых нейронная сеть должна выучить (сложные) закономерности, которые могут лежать в основе видов ирисов, чтобы правильно их классифицировать. Однако это предполагает, что будущие случаи будут демонстрировать закономерности, схожие с теми, которые использовались для обучения нейронной сети.
---> Переменные <---
Независимые переменные: (1) длина чашелистика (см), (2) ширина чашелистика (см), (3) длина лепестка (см) и (4) ширина лепестка (см). Однако сходство независимых переменных затрудняет классификацию. Зависимая переменная соответственно содержит характеристики 0 для "Versicolor" и 1 для "Virginica" для базовых видов ириса. Переменные масштабируются одинаково и не требуют дальнейшей стандартизации.

---> Нейроны <---
Нейроны в нейронной сети являются основными строительными блоками, способными обрабатывать информацию. Они получают входные данные, обрабатывают их, а затем генерируют соответствующие выходные данные. Нейроны могут быть связаны с другими нейронами, что означает, что входные данные одного нейрона обычно основаны на выходных данных другого нейрона. Небольшая нейронная сеть, отображаемая по умолчанию, изначально показывает 11 нейронов во всех слоях, в то время как более крупная нейронная сеть показывает 17 нейронов во всех слоях.
---> Слои <---
Слои в нейронной сети представляют собой группы нейронов, которые работают вместе для обработки входных данных и совместного генерации выходных данных. Взаимодействие между входным слоем, являющимся первым слоем нейронной сети для ввода данных, скрытыми слоями, которые могут распознавать сложные паттерны между входным слоем и выходным слоем, и выходным слоем, который, как последний слой нейронной сети, выдает ответ модели ИИ, имеет решающее значение. Небольшая нейронная сеть, отображаемая по умолчанию, основана на 4 слоях, а более крупная нейронная сеть — на 5 слоях. Нажатие кнопки "Начать обучение" запускает обучение нейронной сети и впоследствии предоставляет информацию об используемых функциях активации, параметрах и точности модели:
---> Эпохи <---
Эпохи — это полные проходы по всем данным, используемым для процесса обучения. Имея данные под рукой, это означает, что нейронная сеть один раз просмотрела и обработала каждый случай из данных. Нейронной сети обычно требуется несколько эпох для распознавания сложных паттернов. Поэтому этот так называемый гиперпараметр необходимо выбирать с осторожностью. Если нейронная сеть проходит только небольшое количество эпох, у нее может не хватить времени для распознавания сложных паттернов в данных (ключевое слово: недообучение). Если нейронная сеть проходит слишком много эпох, она может начать так хорошо изучать обучающие данные, что будет очень хорошо подходить к данным из процесса обучения, но эта подгонка не может быть перенесена на другие данные (ключевое слово: переобучение). Нейронная сеть, отображаемая по умолчанию, изначально настроена на 100 эпох.
---> Скорость обучения <---
Скорость обучения также является гиперпараметром и влияет на то, как быстро или медленно нейронная сеть учится на своих ошибках. Она контролирует размер шагов, которые сеть делает при корректировке весов в процессе обучения. Слишком высокая скорость обучения может привести к тому, что модель пропустит оптимальное решение, а слишком низкая скорость обучения может сделать обучение очень медленным и неэффективным. По умолчанию скорость обучения для нейронной сети, отображаемой по умолчанию, составляет 0,05 и может быть скорректирована соответствующим образом.

---> Функции активации <---
Функции активации определяют, насколько сильно активируется нейрон и какой выходной сигнал он передает на следующий слой. Они помогают отфильтровать нерелевантную информацию и усилить релевантные паттерны. Часто используемые функции активации, хранящиеся в нейронных сетях учебника, — это сигмоида, гиперболическая тангенса, выпрямленная линейная единица и выпрямленная линейная единица с утечкой. Ниже показано, какие функции активации использовались в каких слоях:
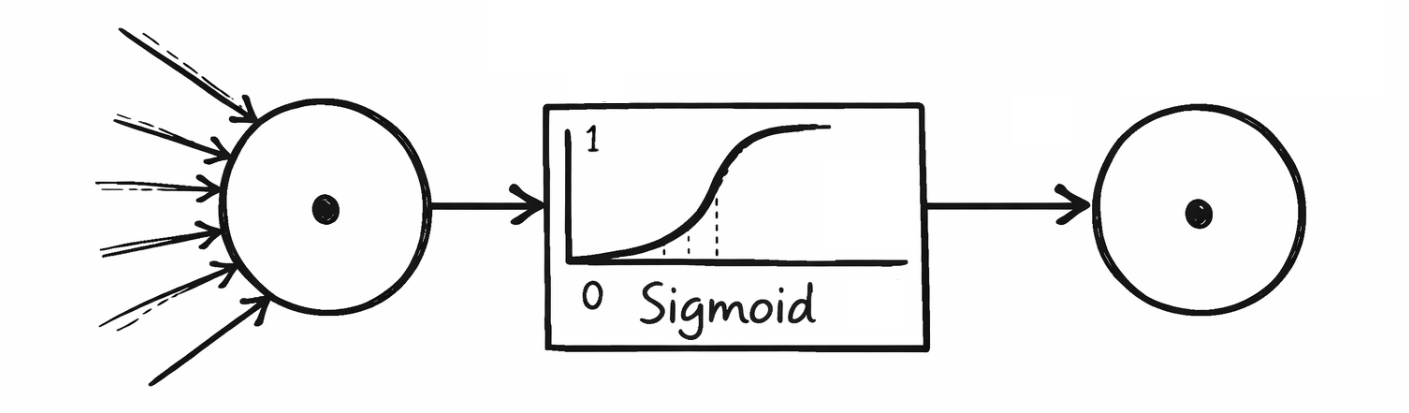
---> Математическая основа <---
Сигмоида выдает значения в диапазоне (0, 1) и часто используется в выходном слое бинарных классификаторов для вычисления, например, вероятности 1 "Virginica".
Гиперболическая тангенса, с другой стороны, выдает значения в диапазоне (-1, 1) и ведет себя аналогично сигмоиде, но является более симметричной и выгодной, когда выходные данные должны быть центрированы. Rectified Linear Unit — одна из наиболее часто используемых функций активации и возвращает входное значение напрямую, если оно больше 0, в противном случае выводится 0. Однако это может привести к отключению нейронов в среднесрочной и долгосрочной перспективе во время процесса обучения (ключевое слово: мертвые нейроны). Вариантом этой функции является Leaky Rectified Linear Unit, которая допускает небольшой наклон для отрицательных значений, чтобы обеспечить небольшую активацию даже при отрицательных входных данных и тем самым уменьшить проблему мертвых нейронов.

---> Архитектура нейронной сети <---
Обучение нейронной сети постепенно корректирует веса и смещения в качестве параметров, которые можно идентифицировать в базовой архитектуре нейронной сети. Веса (w) и смещения (b) располагаются в том порядке, в котором они выводятся соответствующими слоями или вводятся в последующие слои. Первый скрытый слой получает входные значения четырех независимых переменных из исходных данных входного слоя, поэтому в архитектуре нейронной сети для весов предусмотрено четыре столбца. Эти четыре столбца представляют количество нейронов в предыдущем слое, т. е. входном слое. Строки представляют количество нейронов в текущем слое, которое в данном примере составляет четыре нейрона в первом скрытом слое. Четыре нейрона не только передают свои веса в последующий слой, но и дополняются смещениями из процесса обучения. Используемая здесь математическая процедура известна как умножение матриц. В выходном слое в конечном итоге есть только один нейрон, который может классифицировать между 0 и 1 для "Versicolor" или "Virginica". Результирующая архитектура нейронной сети выглядит следующим образом:
---> Веса <---
Веса определяют силу связи между нейронами в соседних слоях сети. Вес умножает входные значения перед их передачей следующему нейрону (ключевое слово: умножение матриц). Более высокие значения веса усиливают входной сигнал, более низкие — ослабляют его.
---> Смещения <---
Смещения — это дополнительные значения, которые можно использовать для сдвига выхода нейрона. Это позволяет нейронной сети учиться более гибко и адаптироваться к конкретным требованиям. Пример: без соответствующего смещения нейрон мог бы иметь выход только 0, если входные значения также равны 0. Смещение предотвращает это, чтобы сохранить входные значения для дальнейшего процесса обучения.

---> Матрица путаницы <---
Матрица путаницы — это таблица, используемая для оценки эффективности модели классификации. Она показывает, насколько хорошо модель предсказывает различные классы, сравнивая фактические значения с прогнозируемыми. Матрица обычно состоит из четырех полей. True Positive (TP): количество правильных положительных прогнозов (модель говорит "положительно", и это действительно "положительно"). False Positive (FP): количество неправильных положительных прогнозов (модель говорит "положительно", но на самом деле это "отрицательно"). True Negative (TN): количество правильных отрицательных прогнозов (модель говорит "отрицательный", и он также является "отрицательным"). False Negative (FN): количество неправильных отрицательных прогнозов (модель говорит "отрицательный", но на самом деле он является "положительным"). На основе обученной нейронной сети получается следующая матрица путаницы:
---> Точность <---
Точность нейронной сети — один из наиболее распространенных показателей, используемых для оценки эффективности модели классификации. Он указывает, как часто модель делала правильные прогнозы. Точность рассчитывается путем деления количества правильных прогнозов (как положительных, так и отрицательных) на общее количество прогнозов. Однако точность является подходящим показателем только в том случае, если ни один из случаев со значениями признаков 0 или 1 не представлен в недостаточной или избыточной степени.

---> Оптимизация <---
Наконец, ложные отрицательные и ложные положительные результаты можно считать неверными прогнозами модели ИИ в базовом наборе данных (Скачать: CSV). Цель здесь состоит в том, чтобы выявить особенности в отдельных случаях, которые отклоняются от выученных шаблонов нейронной сети. Это может не только позволить оптимизировать нейронную сеть посредством переобучения, модификации гиперпараметров или корректировки данных, но и дать понимание ограничений, которые необходимо учитывать при использовании нейронной сети с данными:
---> Заключительные замечания <---
Ручная оптимизация возможна вне учебного курса с использованием языка программирования, такого как Python или MicroPython, для того чтобы переносить модели ИИ в профессиональный контекст с учетом конкретных требований. Этот учебник основан на открытой платформе, которая прозрачно отображает все параметры и гиперпараметры нейронной сети, позволяя гибко адаптировать модели ИИ и сделать их объяснимыми — например, количество нейронов и слоев, а также используемые функции активации, включая экспорт на микроконтроллер, такой как Raspberry Pi Pico (ссылка: AI-ANNE). Что касается классификации ирисов, следует отметить, что такие модели ИИ следует понимать лишь как вспомогательные системы и использовать их, например, для предоставления подсказок при увеличении числа случаев. То, что предоставляемые моделью ИИ подсказки не обязательно являются корректными, было продемонстрировано на примере ложных положительных и ложных отрицательных результатов. Человеческий опыт и экспертиза не могут быть заменены моделью ИИ.


Prof. Dr. habil. Dennis Klinkhammer
www.STATISTICAL-THINKING.de