






---> Temas <---
En este tutorial, se puede entrenar una red neuronal directamente en el navegador. Se describen la estructura y el funcionamiento de una red neuronal como base de los modelos de IA, y se presentan las neuronas y las capas como conceptos básicos esenciales de las redes neuronales. Además, se introducen el número de épocas y la tasa de aprendizaje asociada como los denominados hiperparámetros, que pueden influir significativamente en el proceso de entrenamiento de los modelos de IA. Por último, el proceso de entrenamiento de la red neuronal se puede utilizar para ilustrar el concepto de funciones de activación, que determinan cómo se convierten los parámetros aprendidos en salidas como pesos y sesgos. Si estos se identifican de forma transparente, los modelos de IA se pueden adaptar y optimizar a requisitos específicos. A continuación, se puede evaluar la precisión del modelo utilizando la matriz de confusión y la precisión resultante. Por último, una visión de los falsos negativos y los falsos positivos permite realizar un análisis caso por caso basado en datos para evaluar el proceso de entrenamiento, la calidad de los datos utilizados y la calidad del modelo de IA.
---> Objetivos <---
En general, el tutorial se centra en los conceptos básicos esenciales de las redes neuronales, una presentación simplificada de los fundamentos matemáticos, la interpretabilidad resultante de los resultados y las posibilidades de optimización. El objetivo general del tutorial es proporcionar una explicación transparente del funcionamiento de las redes neuronales con el fin de promover una mejor comprensión de los modelos de IA.

---> Dataset <---
El tutorial se basa en un conjunto de datos (Descargar: CSV) para clasificar especies de iris, con información sobre la longitud y anchura de los sépalos y pétalos. El conjunto de datos contiene un total de cuatro variables independientes que pueden utilizarse para clasificar los iris. Además, hay una variable dependiente que proporciona información sobre la especie de iris en cuestión. Por lo tanto, se trata de casos ya conocidos, a partir de los cuales la red neuronal debe aprender los patrones (complejos) que pueden subyacer a las especies de iris para clasificarlas correctamente. Sin embargo, esto presupone que los casos futuros presentarán patrones similares a los utilizados para entrenar la red neuronal.
---> Variables <---
Las variables independientes son: (1) longitud del sépalo (cm), (2) anchura del sépalo (cm), (3) longitud del pétalo (cm) y (4) anchura del pétalo (cm). Sin embargo, la similitud de las variables independientes dificulta la clasificación. La variable dependiente contiene, en consecuencia, las características 0 para "Versicolor" y 1 para "Virginica" para las especies de iris subyacentes. Las variables se escalan por igual y no requieren una estandarización adicional.

---> Neuronas <---
Las neuronas de una red neuronal son los componentes básicos que pueden procesar información. Reciben información, la procesan y luego generan la respuesta correspondiente. Las neuronas pueden conectarse con otras neuronas, lo que significa que la información que recibe una neurona suele basarse en la respuesta de otra neurona. La pequeña red neuronal que se muestra por defecto muestra inicialmente 11 neuronas en todas las capas, mientras que la red neuronal más grande muestra 17 neuronas en todas las capas.
---> Capas <---
Las capas de una red neuronal son grupos de neuronas que trabajan juntas para procesar los datos de entrada y generar conjuntamente una salida. La interacción entre la capa de entrada, como primera capa de la red neuronal para la entrada de datos, las capas ocultas, que pueden reconocer patrones complejos entre la capa de entrada y la capa de salida, y la capa de salida, que como última capa de la red neuronal emite la respuesta de un modelo de IA, es crucial. La pequeña red neuronal que se muestra por defecto se basa en 4 capas, mientras que la red neuronal más grande se basa en 5 capas. Al hacer clic en el botón "Iniciar entrenamiento", se entrena la red neuronal y, posteriormente, se proporciona información sobre las funciones de activación, los parámetros y la precisión del modelo utilizados:
---> Épocas <---
Las épocas son pasadas completas por todos los datos utilizados para el proceso de entrenamiento. Con los datos disponibles, esto significa que la red neuronal ha visto y procesado cada caso de los datos una vez. Una red neuronal suele necesitar varias épocas para reconocer patrones complejos. Por lo tanto, este hiperparámetro debe elegirse con cuidado. Si la red neuronal solo pasa por un pequeño número de épocas, es posible que no tenga tiempo suficiente para reconocer los patrones complejos de los datos (palabra clave: subajuste). Si la red neuronal tiene demasiadas épocas, puede empezar a aprender los datos de entrenamiento tan bien que se ajuste muy bien a los datos del proceso de entrenamiento, pero este ajuste no se puede transferir a otros datos (palabra clave: sobreajuste). La red neuronal que se muestra por defecto está preconfigurada inicialmente en 100 épocas.
---> Tasa de Aprendizaje <---
La tasa de aprendizaje también es un hiperparámetro e influye en la rapidez o lentitud con la que la red neuronal aprende de sus errores. Controla el tamaño de los pasos que da la red al ajustar los pesos durante el proceso de entrenamiento. Una tasa de aprendizaje demasiado alta puede hacer que el modelo omita la solución óptima, mientras que una tasa de aprendizaje demasiado baja puede hacer que el entrenamiento sea muy lento e ineficaz. La tasa de aprendizaje predeterminada para la red neuronal que se muestra por defecto es 0,05 y se puede ajustar según corresponda.

---> Funciones de Activación <---
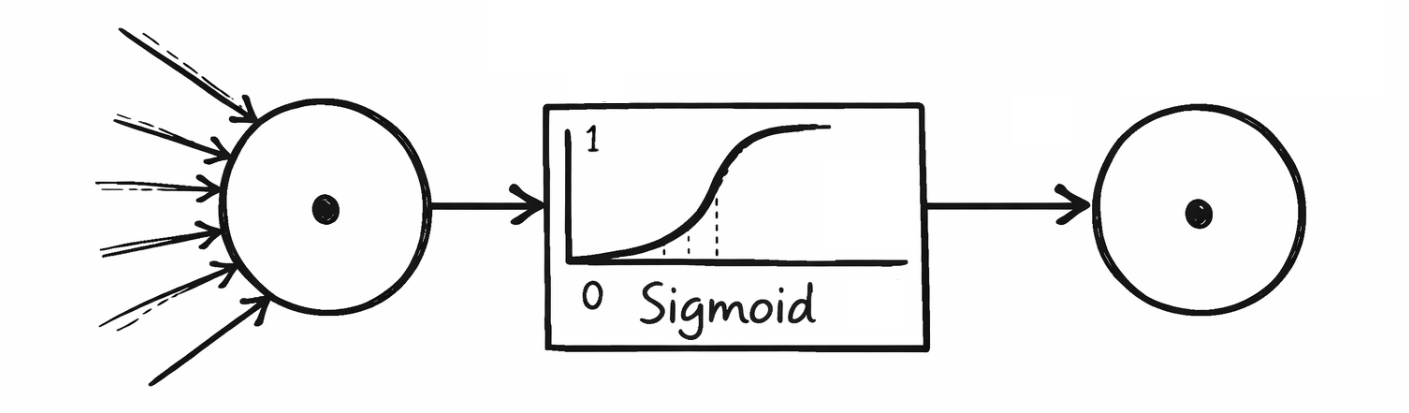
Las funciones de activación determinan la intensidad con la que se activa una neurona y qué salida transmite a la siguiente capa. Ayudan a filtrar la información irrelevante y refuerzan los patrones relevantes. Las funciones de activación más utilizadas y almacenadas en las redes neuronales del tutorial son la sigmoide, la tangente hiperbólica, la unidad lineal rectificada y la unidad lineal rectificada con fuga. A continuación se muestra qué funciones de activación se utilizaron en cada capa:
---> Antecedentes Matemáticos <---
La sigmoide genera valores en el rango (0, 1) y se utiliza a menudo en la capa de salida de los clasificadores binarios para calcular, por ejemplo, la probabilidad de 1 "Virginica". La Tangente Hiperbólica, por otro lado, genera valores en el rango (-1, 1) y se comporta de manera similar a la Sigmoide, pero es más simétrica y ventajosa cuando la salida debe centrarse. La Unidad Lineal Rectificada es una de las funciones de activación más utilizadas y devuelve directamente el valor de entrada si es mayor que 0; de lo contrario, se genera un 0. Sin embargo, esto puede provocar que las neuronas se desactiven a medio o largo plazo durante el proceso de entrenamiento (palabra clave: neuronas muertas). Una variante de esta es la Unidad Lineal Rectificada con Fuga, que permite una pequeña pendiente para los valores negativos con el fin de permitir una pequeña activación incluso con entradas negativas, reduciendo así el problema de las neuronas muertas.

---> Architecture of a Neural Network <---
El entrenamiento de una red neuronal ajusta gradualmente los pesos y sesgos como parámetros, que pueden identificarse en la arquitectura subyacente de la red neuronal. Los pesos (w) y sesgos (b) se ordenan según el orden en que son generados por las respectivas capas o introducidos en las capas posteriores. La primera capa oculta recibe los valores de entrada de las cuatro variables independientes de los datos originales de la capa de entrada, por lo que se proporcionan cuatro columnas para los pesos en la arquitectura de la red neuronal. Estas cuatro columnas representan el número de neuronas de la capa anterior, es decir, la capa de entrada. Las filas representan el número de neuronas de la capa actual, que en este ejemplo es de cuatro neuronas en la primera capa oculta. Las cuatro neuronas no solo transmiten sus pesos a la capa siguiente, sino que estos se complementan con los sesgos del proceso de entrenamiento. El procedimiento matemático utilizado aquí se conoce como multiplicación de matrices. En la capa de salida, solo hay una neurona, que puede clasificar entre 0 y 1 para "Versicolor" o "Virginica". La arquitectura resultante de la red neuronal tiene el siguiente aspecto:
---> Pesos <---
Los pesos determinan la fuerza de la conexión entre las neuronas en capas adyacentes de la red. Un peso multiplica los valores de entrada antes de que se transmitan a la siguiente neurona (palabra clave: multiplicación de matrices). Los valores de peso más altos amplifican la entrada, mientras que los valores más bajos la debilitan.
---> Sesgos <---
Los sesgos son valores adicionales que se pueden utilizar para modificar la salida de una neurona. Esto permite que la red neuronal aprenda de forma más flexible y se adapte a requisitos específicos. Ejemplo: sin un sesgo correspondiente, una neurona solo podría tener una salida de 0 si los valores de entrada también son 0. El sesgo evita esto con el fin de conservar los valores de entrada para el proceso de entrenamiento posterior.

---> Matriz de Confusión <---
Una matriz de confusión es una tabla que se utiliza para evaluar el rendimiento de un modelo de clasificación. Muestra la precisión con la que el modelo predice diferentes clases comparando los valores reales con los valores predichos. La matriz suele constar de cuatro campos. True Positives (TP): el número de predicciones positivas correctas (el modelo dice "positivo" y también es "positivo"). False Positives (FP): el número de predicciones positivas incorrectas (el modelo dice "positivo", pero en realidad es "negativo"). True Negatives (TN): el número de predicciones negativas correctas (el modelo dice "negativo" y también es "negativo"). False Negatives (FN): el número de predicciones negativas incorrectas (el modelo dice "negativo", pero en realidad es "positivo"). Basándose en la red neuronal entrenada, se obtienen los siguientes resultados de la matriz de confusión:
---> Precisión <---
La precisión de una red neuronal es una de las métricas más comunes utilizadas para medir el rendimiento de un modelo de clasificación. Indica la frecuencia con la que el modelo ha realizado la predicción correcta. La precisión se calcula dividiendo el número de predicciones correctas (tanto positivas como negativas) por el número total de predicciones. Sin embargo, la precisión solo es una métrica adecuada si ninguno de los casos con valores de característica 0 o 1 está infrarrepresentado o sobrerrepresentado.

---> Optimization <---
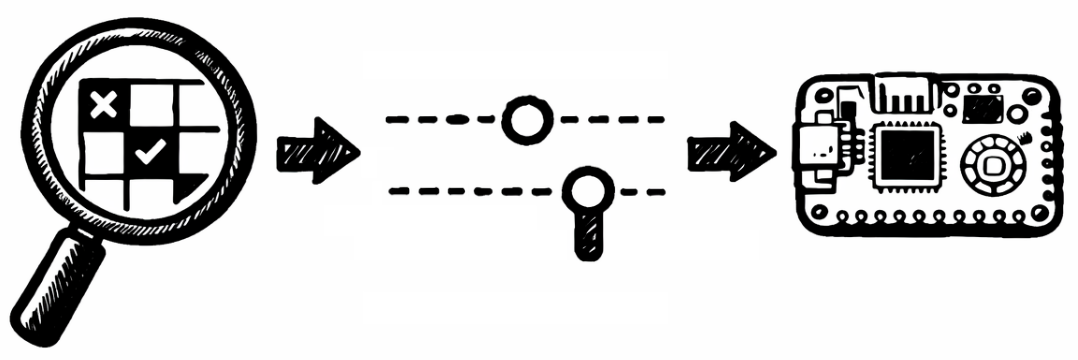
Por último, los falsos negativos y los falsos positivos pueden considerarse predicciones incorrectas del modelo de IA en el conjunto de datos subyacente (Descargar: CSV). El objetivo aquí es identificar cualquier característica especial en casos individuales que se desvíe de los patrones aprendidos por la red neuronal. Esto no solo puede permitir optimizar la red neuronal mediante un nuevo entrenamiento, hiperparámetros modificados o datos ajustados, sino que también puede proporcionar una comprensión de las limitaciones que deben tenerse en cuenta al utilizar una red neuronal con los datos dados:
---> Observaciones Finales <---
La optimización manual es posible fuera del tutorial utilizando un lenguaje de programación como Python o MicroPython para transferir modelos de IA al contexto profesional según sea necesario. Este tutorial se basa en un marco de código abierto que muestra de forma transparente todos los parámetros e hiperparámetros de una red neuronal, lo que permite adaptar los modelos de IA de forma flexible y hacerlos explicables, por ejemplo, el número de neuronas y capas, así como las funciones de activación utilizadas, incluida la exportación a un microcontrolador como el Raspberry Pi Pico (Enlace: AI-ANNE). En lo que respecta a la clasificación de los iris, cabe señalar que estos modelos de IA solo deben entenderse y utilizarse como sistemas de asistencia, por ejemplo, para proporcionar información en caso de que aumente el número de casos. El hecho de que la información proporcionada por un modelo de IA pueda no ser correcta quedó ilustrado por los falsos positivos y los falsos negativos. La experiencia y los conocimientos humanos no pueden ser sustituidos por el modelo de IA.


Prof. Dr. habil. Dennis Klinkhammer
www.STATISTICAL-THINKING.de